In early 1990s, I used STOS Basic on Atari ST for a while, then went over to AMOS on Amiga.
STOS still had line numbers(!) and as far as I remember it did not have procedures. AMOS crammed together a lot of features and resembles Sinclair QL SuperBASIC in some respects.
I was spoiled with AMOS and Basic generally in that just with hitting F1/RUN my program would run in a second. So I've never been especially tolerant towards slow build times.
Blitz Basic helped make more system-friendly code but it was also somewhat trickier to get into.
Installing AMOS Pro with the compiler takes some effort but without the compiler and a hard disk I wouldn't really bother with it.
Acceleration is very useful too, especially in a setup where a modern PC is used for writing the source and compiling it on a super-fast Amiga emulator. I'll discuss this further below.
Find all the AMOS Pro disks, then the Compiler disk images which has the necessary update/patch. Perform the update on the disk images (couldn't get it to work on an already existing HD install) and then install them to HD.
AMOS basics
The following program opens a 16-colour low resolution screen, removes the cursor and flashing. Then it sets up a few colours and clears the screen.
Screen Open 0,320,240,16,Lowres
Curs Off
Flash Off
Paper 0
Ink 1
Pen 1
Cls
Palette 0,$FFF,$F00,$F
Hide
Sprite Update Off
Sprite Off
Print "Hello World!"
Amos To Front
Do
I$=Inkey$
If i$="q" Then End
Loop
Using Hide, Sprite Update Off and Sprite Off together is redundant, but goes to show all this variety exists. (Hide simply hides mouse cursor)
Amos to Front brings everything on top. The Compiler can be set to have Amos in the back by default. This way I can be absolutely sure the first thing the executable displays is something I choose, and not the orange AMOS screen with flashing cursor.
Editor and procedures
Compared to modern coding environments, the editor shows relatively few lines. Another problem is that you cannot really split the source into multiple files, so it will easily grow in size. This is something I didn't care about back in the day but I finally have come to see this as valuable.
But at least it's possible to close and open procedures. This means that for a longer program, having most of the code as closed procedures helps keep the source length manageable.
 |
| _CIRCLE here is poor use of Procedure |
There is some overhead for calling procedures and the compiler can't see a difference between a simple call and a structurally complex one. So, I'd avoid intensively calling procedures. A long FOR loop that calls a procedure to do a minor task can be 2-3 times as slow than one that doesn't.
For example there could be a procedure that draws a screen using 200 tiles, but these individual tiles should not be drawn using procedure calls.
Another editor quirk is the procedure and variable names are always automatically upper-cased. So it's less easy to make any useful distinction between procedures, variables, global variables and "constants" (not that AMOS really has constants).
I've done this: All procedures are preceded with _ and all global variables are indicated with G_ so that for example G_MAXITEMS is a global variable and _CLEARITEMS is a procedure.
Parameters can be passed to procedures between brackets:
Procedure _ADDITEM[TYPE,X,Y]
print "I'm adding type ";TYPE
print "at coordinates ";X;" ";Y
End Proc
These parameter names are local to the procedure, so I could call another procedure from within this procedure that also uses TYPE, X and Y (integer) variables as parameters. So far so good.
Although there's a neat way to return values from procedures, these parameters are clumsily referred by using PARAM after the procedure call.
_ADDITION[2+2]
print PARAM
Procedure _ADDITION[X1,Y1]
RESULT=X1+Y1
End Proc [RESULT]
So, X=_ADDITION[2+2] is not possible.
POP PROC exits the procedure. POP PROC [RESULT] puts the value in PARAM/PARAM$, otherwise the procedure returns nothing.
In 1990s I mostly used a single global variable like RES to store procedure outputs, and simply avoided using procedure results.
So, although the AMOS procedures elevate the language far above BASICs that don't have them, they are not exactly as powerful as c or Java functions.
Causes and effects
AMOS has quite rigorous syntax for if-endif structures.
I can have the normal BASIC style...
if FLAG=0 then print "You're Dead!": print "More"
...and...
if FLAG=0
print "You're Dead!"
print "More"
end if
...is fine too, but...
if FLAG=0
if FLAG2=0 then print "You're Dead!": print "More"
if FLAG2=1 then print "You're Alive!"
end if
is illegal, as it combines if-endif and then.
So I have to do:
if FLAG=0
if FLAG2=0
print "You're Dead!"
print "More"
end if
if FLAG2=1
print "You're Alive!"
end if
end if
...which is kind of clean but it can be annoying. AND, OR, ELSE and ELSE IF are helpful here, though.
"Cross-developing" AMOS
Above, I complained about the AMOS editor. But there's another way.
After the AMOS Compiler has been properly installed, it also works from the Amiga CLI. APCmp is the command:
APCmp source.AMOS INCLIB
INCLIB ensures the outcome is really stand alone and doesn't need an additional library file with the distribution.
Interestingly enough, APCmp can also compile ASCII formatted files, which means I'm not limited to using the AMOS editor. (Sources in AMOS editor are always tokenized).
I'll skip over the idea of using some other Amiga editor for typing the source, and instead use a modern code editor in Linux.
The downside is that the APCmp first tokenizes the ASCII source and then "compiles" the file, and the tokenization phase is what takes a lot of time.
But this is not the end. Although my Raspberry Amibian setup can be too slow for this, it doesn't mean everything is. So, using UAE in my main Linux box, setting the processor/accelerator to Blizzard 1230 IV, the resulting "Amiga" is considerably faster than the Amibian. Then the AMOS tokenization/compilation time will be shrunk to almost nothing for any reasonably sized source.

This means I can edit my AMOS source in sublime-text in Linux and compile with CTRL+B build command. This needs a Makefile/script that combines different separate files in the project folder and dumps the thing over to the UAE Amiga disk image folder.
Something like this:
cat *.txt > source.asc
cp source.asc /path/to/amiga/harddisk/folder/amosstuff/source.asc
So I can have any txt file as part of my source without explicitly defining them in the Makefile or the script.
Yes, CAT combines the original sources in alphabetic order, so if this approach is taken some care should be taken when naming files. As all the source snippets are filled with procedures, the order doesn't matter that much.
I can still name a file aaa_main.txt if I want a particular block to come up first. One thing to remember is that global variables need to be declared before they are used.
On Amiga side I still need to run the compiler from CLI, perhaps using a short script that both compiles and runs the program:
APCmp source.asc INCLIB WB NODEF
source
I saved this as "build" on the Amiga project folder and then used "execute build" to run it from the CLI.
(INCLIB means the library is integrated with the outcome file. WB puts workbench back on start and NODEF means no default screen will be opened.)
Of course, it is only at this stage it will be revealed if there are errors in the source, and not inside the Linux editor. Also, the line numbers in the errors refer to the source.asc file, but it's not too hard to check that in the Linux side.
AMOS editor is still friendlier about errors and easier for debugging. But the fast speed of the UAE environment means that if the code crashes totally, it doesn't take too long to get back to the command line.
By the way, writing Processing/Java and AMOS in same session can be confusing! AMOS procedure inputs are marked with [ and ], dimensioned arrays with ( ), with Processing it's the exact opposite. With AMOS, you can't have ; at the end of the line, equality checks are = and not == and so on and on.
The subtly dangerous thing with AMOS is that as variables don't have to be declared, I can mistype a variable name and it does not register as an error.
A syntax pre-checker at the Linux end might be helpful. Also, while at it, allow more modern syntax and have procedures converted to GOSUBs or even unrolled, when possible.
So, perhaps goodbye to fiddling with Amiga keymaps and AMOS editor idiosyncrasies? Of course I'll lose that AMOS feeling. Snif.
Hiding AMOS
I already talked some about Amos to Front and hiding the "orange screen" effect that plagued many AMOS programs.
I used to be careful with hiding if a program was written with AMOS. This made sense as often the first impressions are important. If anyone saw it was a BASIC program to begin with, it might get a negative response. Although some might go "wow, was this really made in AMOS?!"

Apart from the orange screen, AMOS programs can be revealed by using Amiga-A to flip back and forth between the program and workbench, or using Control-C to break out. These might not be uncommon key combinations, but together they can be revealing.
BREAK OFF instruction can remove the latter, and AMOS LOCK disables the Front/Back switching. The counterpart is AMOS UNLOCK. Locking can be unfriendly though, considering the programs seem to multitask nicely enough. Yet if I intend to spread the software on a floppy disk image, it might not matter.
Function AMOS HERE results in true or false. With this it's possible to see if AMOS is currently in the back or not. This way the program might be stopped from using CPU too much, but I've not really tried it.
What remains is that if there is file access, and the device is not present, AMOS compiled programs will open an ugly AMOS-like dialogue box.
System friendly?
Although AMOS programs are self-contained, it's still possible to write shell-runnable programs that don't open a screen at all. The string variable COMMAND LINE$ holds the arguments. AMOS executables tend to be huge, so it's not an ideal way to write tiny commands.
Graphics is a thornier issue. In later days, more modern graphics modes came available and software that didn't play nice with these new modes were frowned on.
But Amiga 500 itself is now increasingly recognized as a retro platform on its own right, despite any newer developments. So it is possible to target the Amiga 500 and care less if the program works on some new-fangled Amiga or not.
Looking at the AMOSPro manual, there are ways to access the Amiga libraries so who knows, it might be able to set a system screen/window.
Some speed considerations
To get some more speed out of AMOS, there are some simple guidelines that can be followed.
I already mentioned the dangers of using procedures in a wrong way. I also noticed GOSUB/RETURN is faster than calling a procedure without parameters. This puts to question whether PROCEDURE should be used so much after all.
Integer variables (1,2,3,4...) should be favored. Floating/real number variables (1.0, 2.0, 3.0, 4.0 ...) are indicated with # so that variables like X# and Y# are floats and X and Y are integers.
If no complex evaluation is needed then Add X,1 should be faster than X=X+1 and Inc X should be faster still.
Adding a variable to another such as Add X,Y does not seem to slow down the computation much.
However, after compilation the difference of these tends to shrink to almost nothing. AmosPro allows compilation+running within the editor environment so comparing non-compiled with compiled sources is quite easy. Set TIMER=0 before your test loop and then print TIMER afterwards.
It can be useful to reduce multiplications and complex equations in a loop.
For example:
For I=0 to 99
LOC=BASE+I*32
if peek(LOC)=1 then Inc A
Next I
Consider this instead:
LOC=BASE
For I=0 to 99
if peek(LOC)=1 then Inc A
Add LOC,32
Next I
Again:
For Y=0 to 10
For X=0 to 10
LOC=BASE+X+Y*40
Next X
Next Y
This is faster:
LOC=BASE
For Y=0 to 10
For X=0 to 10
Inc LOC
Next X
Add LOC,29
Next Y
Also, if a calculation like AD=AD+Y*WID needs to be done a lot, first Z=Y*WID and use Add AD,Z instead. (If Z doesn't need to change)
Unrolling is helpful in BASIC too, and the compiled code also benefits from it. So, instead of the first example:
LOC=BASE
For I=0 to 49
if peek(LOC)=1 then Inc A
Add LOC,32
if peek(LOC)=1 then Inc A
Add LOC,32
Next I
AMOS and machine code
Writing 68000 machine code is not super-hard in itself, but on a complex 16-bit computer and OS like the Amiga it's a chore to get something visibly up and running.
I've used AMOS as a frame to which I can add some machine code at speed-critical points.
Just to prove it works:
Reserve As Data 10,65536
Doke start(10),$4E75
Call start(10)
The machine code routine is called from the start of the bank 10, where I have reserved 64K of memory.
Then I have used doke (16-bit length POKE) to write the value that corresponds with RTS so the only thing the routine does is come back to AMOS.
This is a very silly way to insert 16-bit code. It is better to load in an output binary from an assembler:
Reserve As Data 10,65536
Bload "output.bin",start(10)
Call start(10)
Assuming the binary is less than 64K long.
As the start address can be where ever AMOS has reserved the memory area, the code has to be relocatable. This isn't a huge deal, for example vasmm68k knows to produce relocatable and optimized code just as long the ORG/* statement is left out.
Vasmm does a lot to ensure the code is relocatable, but the programmer still has to know some things. For example, it's not possible to move a label address directly to a d-register. It's possible to do move.l #label,a0 because the compiler changes it to lea, but this has no counterpart for d-registers. (Edit: This explanation is not correct, the move instructions have (pc) relative addressing modes just as lea does, it's just that in practice the compiler allowed the use of LEA without explicitly stating a relative addressing mode.)
Register values can be set from AMOS using areg(n) and dreg(n), corresponding with the a and d registers of the 68000. The dreg 0-7 can be freely used whereas a-register 0-3 are available.
This isn't a limitation, for example areg(0) could point to a start address of a memory area that contains a large table of values you want to use from machine code. Or, the table is inside the assembly binary in a reliable location you can access from AMOS.
To give some clarity the start addresses can be variables. E.g. G_REFRESH=Start(10): Call G_REFRESH
I stored a calculation result in a variable that was apparently in 0-255 byte boundary but became something else in the assembler. I learned AMOS had signed the variable during the process. This helped get rid of the sign:
If A<128 then A=A AND $7F: Areg(0)=A
This means that even if AMOS prints the variable content as 84, it might be internally something else. It's possible the transition using areg(0) is buggy, or I have not understood something. If the variable is directly set as A=84: Areg(0)=A there's no trouble.
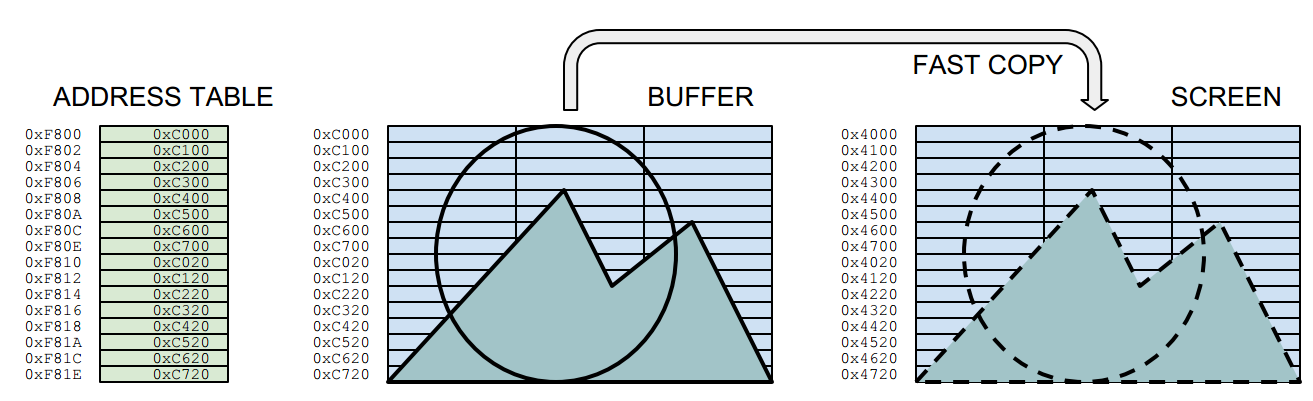
Phybase(bitmap#) and Logbase(bitmap#) are AMOS variables that have the addresses of the current screen bitmaps. If double buffer is on, then Phybase will point to the start of the visible screen and logbase to the "logical", the hidden screen. Screen Swap will change these addresses.
So if you use areg(0)=phybase(0) you can transmit the start of the screen bitmap 0 over to the machine code, for custom graphics routines.
There are a few ways an Amiga can set up a bitmap screen. AMOS reserves screens bitmaps with one bitmap after another and apparently you can't tell AMOS to do otherwise. (The other way would be to store bitmaps so that all bitmap lines follow each other.)
In my experience, drawing grids of 16x16 (or 8x8) tiles with 68K is considerably faster than AMOS at the same job with a PASTE BLOCK loop. This helps a lot in purely tile-based screens.
 |
| Something I've been working on... |
Other than that I don't know if it's wise to try write faster graphics routines than AMOS already does.
As an aside, I found out the hard way there is a difference between how 68000 and 68020 can handle some operations. It's better to have any word-size (move.w) operations on word-aligned addresses, (e.g 0xdf000 is okay, but not 0xdf001).
Even if 68020 doesn't crash on these, the plain 68000 does. I spent some time wondering why particular code did work on the WB3.1 68020 emulator environment but not on the real A500, thinking I'd run out of memory or did some other cock-up.
Obviously byte-size operations (move.b) are fine on any kind of addresses. It's just that when possible, moving words and long words is much more effective.